Archive
Campaign Finance Based Forecasts for the 2010 Midterm Elections
As promised, here are my predictions for the 2010 Midterm Elections. The model parts with poll-based forecasting models in predicting that the Democrats will maintain control of the House. It predicts that Democrats will win between 217 and 238 seats, which translates into a loss of 19 to 40 seats. (The complete set of House predictions is available for downloaded as a .csv or a .xls.)

The histogram displays the predicted number of Democratic Seats from 10,000 bootstrap simulations.
If Congress operated more like a Westminster parliamentary system, fixating on which party will win a majority of seats would be more sensible. In such a setting, after assuming power the majority party (or coalition) is free to enact legislation with as little input from the minority as it pleases. This is not the case in Congress. The past two years have been a constant reminder to Democrats that even large electoral majorities do not grant similar levels of legislative control. Current theories of congressional behavior tell us that the position of the median member of Congress can be as important to policy outcomes as which party is in the majority. An advantage of my forecasting model is that it can predict ideological quantities of interest other than seat shares. For example, I can predict the position of the median member in the next Congress and the extent to which partisan polarization will increase or decrease.
The model projects that the position of the median House member in the 112th Congress will be -0.05 with a 95 percent CI between -0.13 and .13. This represents a sizable shift to the right from the median legislator in the 111th Congress, who was located at -0.24. Yet, this will only bring the median back to where it was during the 110th Congress. To place this in perspective, the median House member in the 111th Congress was in the region of Joe Baca (D-CA) and James Oberstar (D-MN). The model predictions place the median member for the 112th Congress in the region of Arthur Davis (D-AL) and James Marshall (D-GA) but could be as far to the right as John McHugh (R-NY) or former Senator Lincoln Chaffee (R-RI), which is still very moderate. According to the model, even in the best-case scenarios, the House median will be much more moderate than what Republicans experienced during the 104th-109th Congress.
The figure below displays the trend lines for the median House member and the means for each party since 1990. Regardless of which party claims a majority after the election, the model projects an increase in partisan polarization. The mean Republican will experience its largest shift to the right ever recorded, while the mean Democrat also will move further to the left as Republican challengers pick off moderate Democratic incumbents. The general rule of thumb for this election is: the larger Republican gains, the greater the increase in polarization.

I report the model predictions faithfully here, but I remain somewhat skeptical of the model predictions for two reasons. The first is that the realm of campaign finance has undergone changes since the previous election cycle. Not accounting for independent expenditures by outside groups might have biased the model in favor of Democrats. On the other hand, the BCRA arguably represented a much larger shock to the campaign finance system than Citizens United, yet the model predictions for the 2004 Elections were right on target. Moreover, the model does not include any variables that relate to campaign expenditures; it only conditions on fundraising patterns, which remain largely unaffected by Citizens United. The second reason is that the model predicted Democrats would win about 10 seats fewer than they actually did in the 2006 Midterm Elections. It is difficult to determine whether this reflects the Mark Foley October surprise or a failure by the model to account for partisan momentum.
I suspect the model predictions are too generous to Democrats by about 8 to 12 seats. Even with the downward adjustment, I still predict the Democrats will retain their majority, but just barely. This is in line with Sandy Gordon’s forecasting model based on calibrated expert raters. Along with Sandy’s forecasts and the recent polls showing that oversampling of landlines can bias polls in favor of Republicans, my model provides additional evidence that poll-based forecasting models are overstating Republican gains. Fortunately, we won’t have to wait long to find out.
Forecasting House Elections with FEC Records
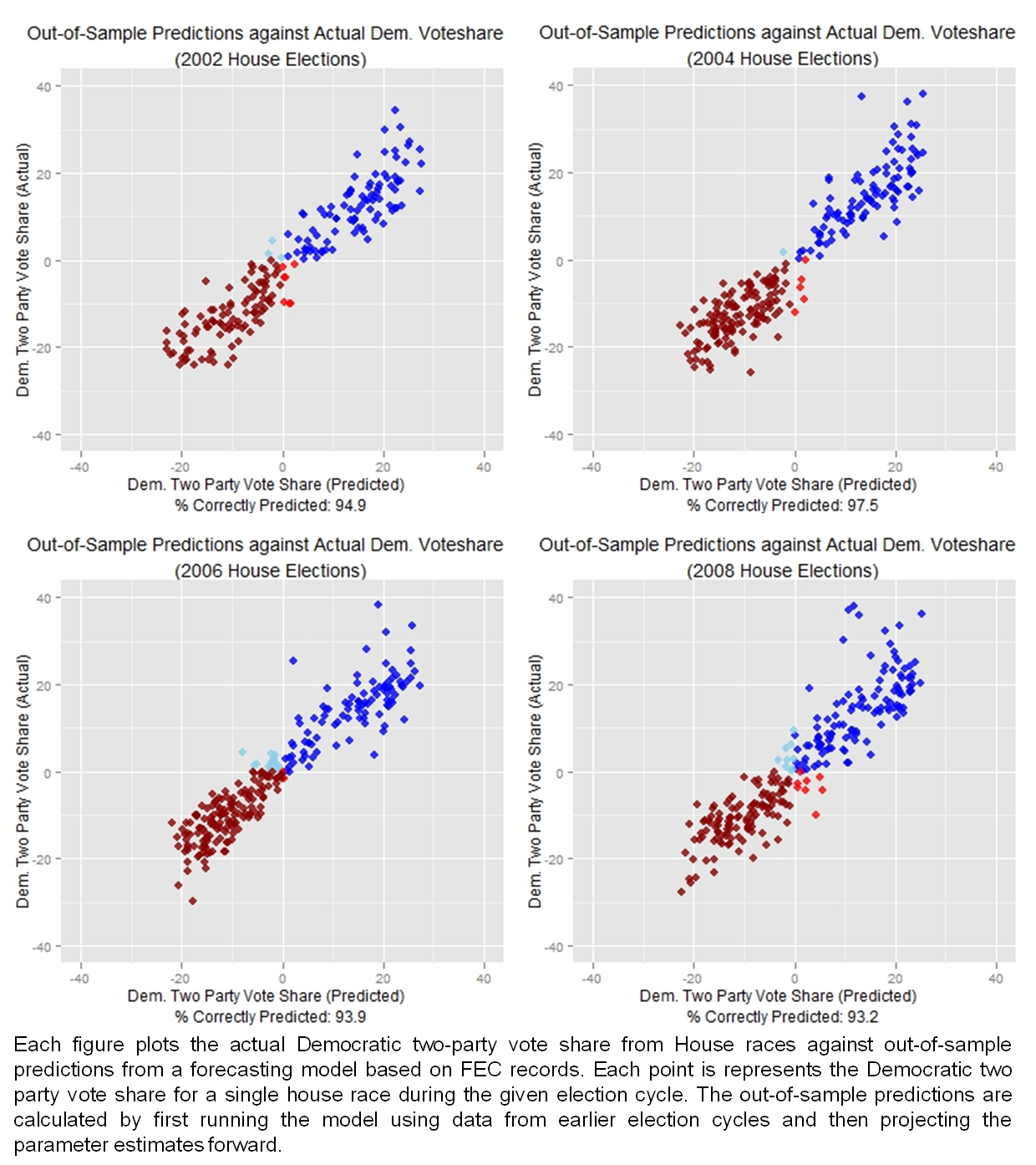
As election day nears, I thought it might be an interesting exercise to see how accurately I could forecast election outcomes using only information derived from campaign finance records. Campaign finance records represent a rich data source that speaks to many areas of U.S. politics. Elections are no exception. I’m not the first to incorporate information on fundraising into a forecasting model. However, to the best of my knowledge, I am the first to attempt to forecast election outcomes based solely on FEC records. Despite the handicap of excluding all information from polls, InTrade, expert raters, and other data sources used to forecast elections, the model’s predictions are remarkably accurate. In fact, the out-of-sample predictions for House races outperform the polls.
Contribution records contain far more useful information than what can be expressed by fundraising tallies. For instance, they provide a way to estimate a reliable set of candidate positions via CFscores. The CFscores update almost in real time as FEC records are released during the course of an election cycle. In other words, we don’t have to wait until the election is over to get ideological measures for candidates. The CFscores enable my forecasting model to account for factors that other models ignore, such as adjusting for whether the ideological extremity of Tea Party candidates will hinder Republican electoral prospects this November. In addition, I can forecast ideological quantities of interest such as how the location of the median member of Congress will change after the election. This is perhaps less useful in terms of the horse-race but is probably a better overall measure for the type of policy we should expect from the next Congress.
Also informative are the patterns of individual donors across elections. I’ve been working on assigning unique contributor IDs that link contribution records from the same donor across election cycles and across state and federal elections. This may not seem like a big deal, but the ability to track the behavior of individual donors across elections cycles unlocks a wealth of information that had previously been trapped inside the dataset. For instance, linking records across years makes it possible to calculate the proportion of a candidate’s funds that came from first-time donors as opposed to veteran contributors. At the level of campaigns, this can convey information about a candidate’s success in activating supporters. At the national level, the median CFscore across all first time donors serves as a good proxy for the enthusiasm gap.
Much of the model’s predictive power is owed to an idea I borrowed from Sandy Gordon. Sandy has an interesting paper in which he uses past performance of expert election raters to calibrate their predictions in future elections. The paper gave me the idea of treating the hundreds of thousands of donors who had given in previous election cycles as de facto expert raters by looking at the percentage of funds given to winning candidates in previous election cycles. The idea behind this is simple. Some contributors give a greater proportion of their money to candidates that go on to win, while others spend the majority of their money on losing candidates. All else equal, the more money a candidate raises from the type of donors who give to winners, the more likely he is to win. (For additional details on what goes into the model, I include at the bottom of this post a description of the other model predictors, as well as links to download the R script and dataset.)
Tom Holbrook over at Politics by the Numbers nicely overviews the accuracy of election polls. He shows that during the 2006 and 2008 election cycles approximately 85 percent of House candidates who led in the polls 45 days before the election went on to win. As a comparison, the out-of-sample predictions from my forecasting model correctly identify the winner in over 94 percent of combined 2002-2008 House elections.
It is worth noting that my sample includes a number of less competitive House races that lack polling data and hence are excluded from the poll based predictions. The larger sample accounts for some of the increase the prediction rate but not all of it.

The model’s seat share predictions are also close to the mark. The table below shows the number of seats won by Democrats that the model predicts above/below the observed outcome (e.g. a value of 4 indicates the model predicts that Democrats would win four more seats than they actually did; a value of -4 indicates the model predicts Democrats would win four fewer seats than they actually did). I ran 1000 bootstrapped simulations for each election cycle to get uncertainty estimates. The first column reports the median value from bootstrapped runs and the other two columns display the upper and lower 95 percent confidence bounds.
|
Median |
CI Lower Bound |
CI Upper Bound |
|
|
2002 |
4 |
-1 |
8 |
|
2004 |
4 |
1 |
6 |
|
2006 |
-12 |
-18 |
-5 |
|
2008 |
-1 |
-1 |
5 |
The predictions are very close to the actual outcome in all but one election cycle. In 2006 the model under predicts Democratic gains by a considerable margin. This might be a result of the Mark Foley factor but I would need more evidence to support that claim. It is just as likely that it reflects a failure of the model to adjust for the effects of partisan momentum in landslide years. (As a note, I noticed that the confidence bounds only contain the observed value in two of the four elections. This suggests that I should probably up the amount of uncertainty in the bootstrapping scheme above the software’s default.)
A major advantage of using campaign finance data to forecast elections is that it costs next to nothing. There is no need to commission polls or pay expert raters. One needs only to collect freely available data and fit a model. That being said, campaign finance based forecasting could have the greatest impact in state level elections where polling data is sparse but fundraising abounds. Although I’m not convinced that they would be, it might be interesting to seeing if the model predictions are as accurate for state elections as they are for federal elections. The catch is that not every state is quite up to speed with the FEC in releasing contribution records to the public in a timely manner, but this problem is fast solving itself as the disclosure process becomes increasingly digitized.
As much as I would like to have predictions ready for the upcoming election, I haven’t had the time to fully organize the dataset. Those forecasts will have to wait until this weekend. In the meantime, I’ve made the dataset and R script available for download for anyone who might be interested.
Predictors
Candidate Positioning: I use candidate CFscores to measure ideology.
Picking Winners: For each contributor, I calculate the percentage of funds given to winning candidates in previous election cycles. Then for each candidate, I calculate the mean value of his contributors weighted by the dollar amounts received.
First-Time Donors: I calculate the percentage of a campaign’s donors that gave the first time during that election cycle. This is intended as a proxy for the enthusiasm gap.
Donor Mood: I construct an aggregate variable by calculating the CFscore of the median first-time donor to proxy public mood.
Fundraising Success: This is measured by the log total amount raised by each candidate and the log sum of unique contributors.
Source of Funds: For each candidate, I calculate the percentages of funds raised from PACs, individual donors, party committees, and self-funding.

{kind=link}